
Malgré une géopolitique internationale toujours plus tendue, malgré les odeurs de crise économique et financière toujours plus fortes, le monde de l’intelligence artificielle continue d’avancer et le précédent billet relatif à ce domaine, pourtant vieux de quelques semaines seulement, semble déjà fort lointain tant les nouveautés se sont accumulées depuis.
Ainsi, les questions posées sur le droit d’auteur pour les IA génératrices d’images (comme MidJourney ou Dall-E par exemple) que ces colonnes évoquaient à la fin de l’année 2022 – et qui n’avaient que très partiellement trouvé de réponses – risquent de se poser à nouveau avec encore plus d’insistance alors que viennent de sortir de grosses nouveautés en matière de musique cette fois-ci.
En effet, en l’espace de quelques semaines sont apparus deux nouveaux moteurs de générations de musique qui permettent de créer différents types de productions musicales, avec ou sans paroles, sur différents styles extrêmement variés depuis la musique “classique” jusqu’au rap en passant par le rock, le blues, la pop ou les musiques électroniques. Ainsi, à partir d’une simple invite de l’utilisateur, l’un et l’autre de moteurs permettent de créer une musique ou une chanson dans le style de son choix ou au hasard de la machine.
Le premier à se faire connaître est Suno dont la production est maintenant assez copieuse. Le moteur d’IA permet des mélanges de genre assez hétéroclites, depuis “l’acoustic acid rock” jusqu’au “swing samba” en passant par le “celtic boogie”. Sans mal, les résultats sont surprenants : la qualité n’est pas différente de ce qu’on entend tous les jours à la radio et les textes ne sont pas tous mauvais, loin s’en faut (et certaines “références” françaises souffrent mal la comparaison avec ces productions mécaniques)… Bref : si on ne tient pas encore le prochain Mozart dans ce moteur d’intelligence artificielle, on se place, en terme de production musicale, dans la moyenne de ce qu’on trouve déjà un peu partout.
Le second, apparu quelques semaines seulement après, offre une qualité de création encore supérieure : Udio répond globalement aux mêmes principes et permet, avec quelques instructions simples concernant le style et l’organisation du morceau que l’on souhaite créer d’obtenir en quelques minutes un résultat tout à fait comparable avec la production musicale courante.
Dans ce contexte, on se demande exactement ce qui va empêcher certaines radios de diffuser en continu les productions choisies de ces moteurs, et on commence à entrevoir un monde où la musique d’ambiance (dans les magasins par exemple) ne sera plus produite par des artistes, enregistrée puis distribuée, mais produite à la volée en fonction du lieu, de l’ambiance choisie par le propriétaire ou de critères du moment. Dans ce cadre, on s’amuse déjà des excitations qui s’empareront (en vain) des personnels chargés des inspections de la SACEM… La collecte des droits d’auteur promet d’être un tantinet plus complexe.
Le marché de la musique commerciale et d’ambiance promet donc d’être abondamment bouleversé par l’arrivée de ces nouveaux moteurs, au même titre que celui des applications de rencontres sur internet : la possibilité, bien réelle, de créer des “copines virtuelles” crédibles – aussi bien du côté visuel que du côté des éventuelles conversations – ouvre depuis peu un marché que certains évaluent à plus d’un milliard de dollars.
Pendant ce temps, les moteurs larges de langage (“LLM”) continuent leur course à la performance, en tentant chaque jour de résoudre des problèmes de plus en plus complexes et abstraits que leur soumettent leurs utilisateurs. Il est fini le temps où les moteurs proposaient très sérieusement des recettes pour cuire les œufs de vache et si les règles communes et les lois les plus basiques de la physique qui nous entoure échappent encore parfois à ces intelligences artificielles, c’est de moins en moins fréquent.
La version 5 de ChatGPT d’OpenAI n’est toujours pas sortie, mais depuis ChatGPT 4, des moteurs concurrents ont affiché des résultats et des métriques particulièrement enthousiasmants. Ainsi, Claude (de la société Anthropic) montre des capacités proches ou supérieures à celle du dernier moteur d’OpenAI.
Mais récemment, c’est Meta, la firme de Mark Zuckerberg, qui a surpris le milieu en publiant Llama3, leur dernier moteur dont il existe à présent deux versions, l’une à 8 milliards de paramètres et l’autre à 70 milliards. Cette dernière affiche des performances comparables ou meilleures que Claude et ChatGPT4… tout en étant intégralement “open source”, c’est-à-dire que l’intégralité du code est disponible pour tous, ce qui permet à des millions de développeurs et de curieux de tester le moteur, de le modifier ou de participer à son évolution.
Ce dernier rebondissement montre plusieurs choses intéressantes.
D’une part, cette course qui s’est établie entre les différentes entreprises pour produire le modèle le plus affûté confirme à quel point le “phénomène” ChatGPT, survenu en novembre 2022, n’était pas qu’une intéressante curiosité.
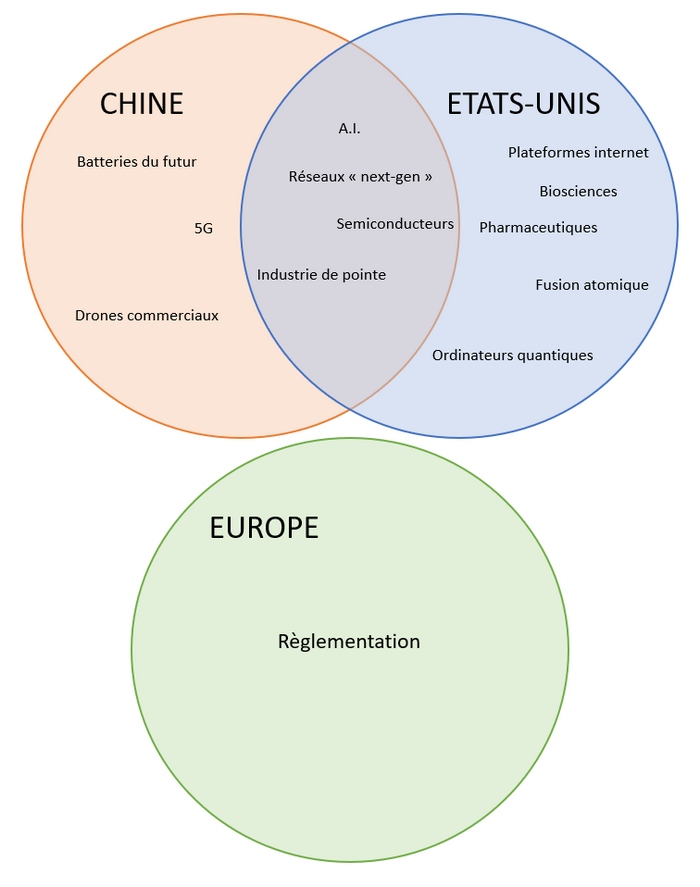
D’autre part, la présence extrêmement modeste de l’Europe dans les sociétés qui se sont lancées dans cette course – seule Mistral, française, semble pouvoir participer – montre une fois encore que les gesticulations européennes, essentiellement à base de régulation, n’ont absolument pas permis l’émergence d’un véritable terreau fertile aux développements de nombreuses entreprises dans le domaine.
Mais surtout, cette compétition montre une fois encore les bienfaits d’une concurrence qui impose une amélioration constante des moteurs et des performances, et l’accélération de la tendance générale à la puissance des modèles proposés. Si, fin 2022, OpenAi semblait disposer d’une véritable suprématie dans le domaine, ce n’est plus le cas à présent.
En somme, les moteurs d’intelligence artificielle sont en train de grignoter le fondement même de certaines professions, depuis les artistes (dans le graphisme et maintenant la musique) jusqu’aux professions littéraires (journalistes ou traducteurs pour ne citer que celles-là), et de plus en plus rapidement, avec une qualité de production, de raisonnement ou de déduction toujours meilleure.
Ce constat peut légitimement inquiéter à peu près tout le monde, d’autant plus que ces moteurs alimenteront les “cerveaux” électroniques de robots humanoïdes dont le développement connaît, lui aussi, de belles avancées.
Cependant, l’arrivée de Llama3 marque deux points très importants dans ces développements.
Le premier est que ce modèle “open source” marche très bien, mieux que prévu même : avec un modèle sensiblement plus petit que la concurrence, on obtient des résultats égaux ou supérieurs à ceux de Chatgpt qui, pour rappel, comporte 1500 milliards de paramètres contre 70 pour le plus gros des Llama3. En fait, ce dernier a beaucoup bénéficié de temps d’entraînement supérieurs et d’une grande qualité des données sources ainsi qu’un meilleur raffinement de l’apprentissage. Au passage, cela peut signifier que les modèles actuels seraient plutôt sous-entraînés et qu’à nombre égal de paramètres, on pourrait espérer avoir des résultats encore bien meilleurs moyennant un entraînement plus long et plus fin.
Du reste, Meta travaille sur le prochain modèle (à 405 milliards de paramètres !) qui pourrait dépasser les modèles actuels, et qui sera lui aussi open source.
Le fait d’être en modèle ouvert évite les dérives de certains moteurs : si Google pouvait tenter de proposer une IA complètement woke, ou si ChatGPT se retrouve châtré avec l’impossibilité de remettre en question certains dogmes du moment (changement climatique anthropique, théorie du genre et autres folies progressistes du même acabit, etc.), le moteur open source peut, lui, tourner sur un environnement complètement indépendant et donc hors des limitations imposées aux précédents.
Oui, nous nous acheminons vraisemblablement vers un monde où chacun pourra disposer de son propre modèle d’IA, entraîné de façon généraliste et spécialisé pour son propre usage, et dont le fonctionnement ne sera limité ni par le fabricant, ni par le politiquement correct. Il est sans doute assez proche le moment où vous pourrez faire fonctionner un agent “open source” sur votre téléphone, sans que cet agent fuite vos données vers des services commerciaux ou gouvernementaux, sans qu’il ait été contraint par l’une ou l’autre agence, l’une ou l’autre société.
Et ceci est une excellente nouvelle.

Aucun commentaire:
Enregistrer un commentaire
Remarque : Seul un membre de ce blog est autorisé à enregistrer un commentaire.