
Décidément, depuis le 30 novembre dernier, date à laquelle le produit a été proposé pour tous, la “révolution” ChatGPT chamboule le paysage informatique en donnant une petite idée de l’état des lieux en matière d’intelligence artificielle, et le paysage sociétal en remettant en cause certaines habitudes pourtant bien ancrées…
ChatGPT, évoqué récemment dans ces colonnes, c’est ce moteur conversationnel basé sur un gros modèle de langage (“Large Language Model”) dont l’entraînement a été réalisé avec des millions de documents en ligne, et qui est capable de générer du texte de manière fluide et naturelle à même de simuler une conversation humaine convaincante.
Dès sa sortie, l’outil d’intelligence artificielle avait défrayé la chronique et voyait son nombre d’utilisateurs augmenter rapidement, à tel point qu’il est à présent utilisé par plus de cent millions d’internautes (oui, vous avez bien lu, 100 millions). De ce point de vue, c’est l’application informatique qui a attiré le plus d’attention humaine dans le temps le plus court : outre la curiosité qui attire, c’est la capacité de la machine à singer un dialogue, à y apporter des réponses sinon exactes au moins superficiellement cohérentes qui étonne le plus.
Devant ce succès, OpenAI, la jeune société qui propose gratuitement ChatGPT, vient de lancer une version payante de son produit. Pour 20 dollars par mois, les Américains d’abord – le reste du monde progressivement – pourront interagir avec le robot conversationnel et obtenir de l’aide sur les sujets qu’il est capable de comprendre. Ainsi, en matière de code, le moteur a montré d’excellentes capacités à assister le programmeur informatique dans son développement, une bonne versatilité dans les langages maîtrisés voire une aide précieuse pour le débogage.

Sans grande surprise, Microsoft, qui a déjà des parts dans OpenAI, a soigneusement remis quelques billets au bot pot : un petit chèque de 10 milliards qui viendront mettre du beurre financier dans les épinards numériques d’OpenAI.
Il faut dire que les idées d’utilisations pratiques d’un tel outil ne manquent pas, depuis l’intégration évidente avec Bing, le moteur de recherche de la firme de Redmond, jusqu’à utiliser par exemple un modèle proche associé à des logiciels de téléconférence comme Teams afin de produire, à la volée, un compte-rendu de réunion, la liste des principales décisions prises ou des actions décidées lors de la réunion tenue en ligne. Apparemment, le secrétariat est amené à évoluer, très, très vite dans les prochains mois, au moins pour ceux qui sont prêts à avoir leurs conversations (ici, celles passées sur Teams) analysées par des fermes de serveurs étrangères…
Devant le succès de ChatGPT et l’intérêt de Microsoft, Google est presque passé en mode “panique” : l’entreprise a bien conscience de l’importance du robot conversationnel et de son impact sur la recherche internet, cœur de métier de Google. Elle a d’ailleurs largement progressé dans sa propre version, Lamda, qu’elle destine plus ou moins à la même chose que ChatGPT en offrant la possibilité aux utilisateurs de Google d’interagir avec. Chaque semaine qui passe est donc cruciale pour Google et toutes les firmes lancées dans l’intelligence artificielle, afin de ne pas voir le marché se refermer trop vite.
Et pendant que les cadres de Google s’agitent pour rattraper ChatGPT, on observe un peu la même fébrilité dans certains établissements scolaires : comme prévu, l’apprentissage tel qu’il est encore pratiqué actuellement va devoir s’adapter assez rudement à ce changement rapide de paradigme ; les professseurs vont devoir modifier leur façon de tester les connaissances de leurs élèves : le risque est maintenant grand de récupérer une production du moteur d’OpenAI à la place d’un devoir personnel. Et s’il est pour le moment encore possible de différencier les productions du robot des productions généralement moins propres (et aussi truffées de fautes d’orthographe) des élèves, les prochaines générations de l’IA textuelle permettront de s’adapter à ces contraintes scolaires de façon beaucoup plus efficace.
Logiquement, ce sont les écoles et universités qui se basent le plus sur les pénibles productions écrites de leurs élèves qui sont le plus à la peine devant ce phénomène : la panique s’est ainsi emparée des enseignants de SciencePo lorsqu’ils ont vu arriver les premiers devoirs rédigés par l’IA : il est en effet difficile de distinguer la soupe plate de l’IA de celle des élèves façonnés par les cours de la célèbre école, au point que la direction a enjoint les professeurs à interdire purement et explicitement l’utilisation ChatGPT.
En cela, l’école est logique : depuis de nombreuses années, elle avait déjà banni toute forme d’intelligence qui aurait constitué un handicap pour par exemple entrer à l’ENA. L’artificielle ne faisait donc pas le poids et son interdiction était inévitable.
Cependant, avec ce succès et l’augmentation exponentielle de l’usage du moteur par des internautes du monde entier, un nouveau souci est apparu très vite : ChatGPT, qui avait été entraîné sur un ensemble déjà largement sélectionné avec soin (et biais afférent), est maintenant de plus en plus châtrée dans ses réponses à mesure que s’amoncellent les requêtes des internautes. OpenAI, consciente qu’un dérapage pourrait coûter cher en image de marque, n’a de cesse d’orienter les réponses pour éviter toute “mauvaise publicité”, c’est-à-dire risquer le politiquement incorrect, tâche ô combien délicate à définir pour une machine, aussi complexe soit-elle.
Malheureusement, ce “politiquement correct” commence furieusement à ressembler à une forme très particulière de censure, de la même nature que celle qu’on retrouve déjà sur certains réseaux sociaux. À tel point que plusieurs internautes ont commencé à réaliser une mesure objective des biais introduits dans la base documentaire et dans les réponses de ChatGPT pour aboutir à la conclusion que le moteur traite de moins en moins similairement les différents démographies auxquelles il est confronté.
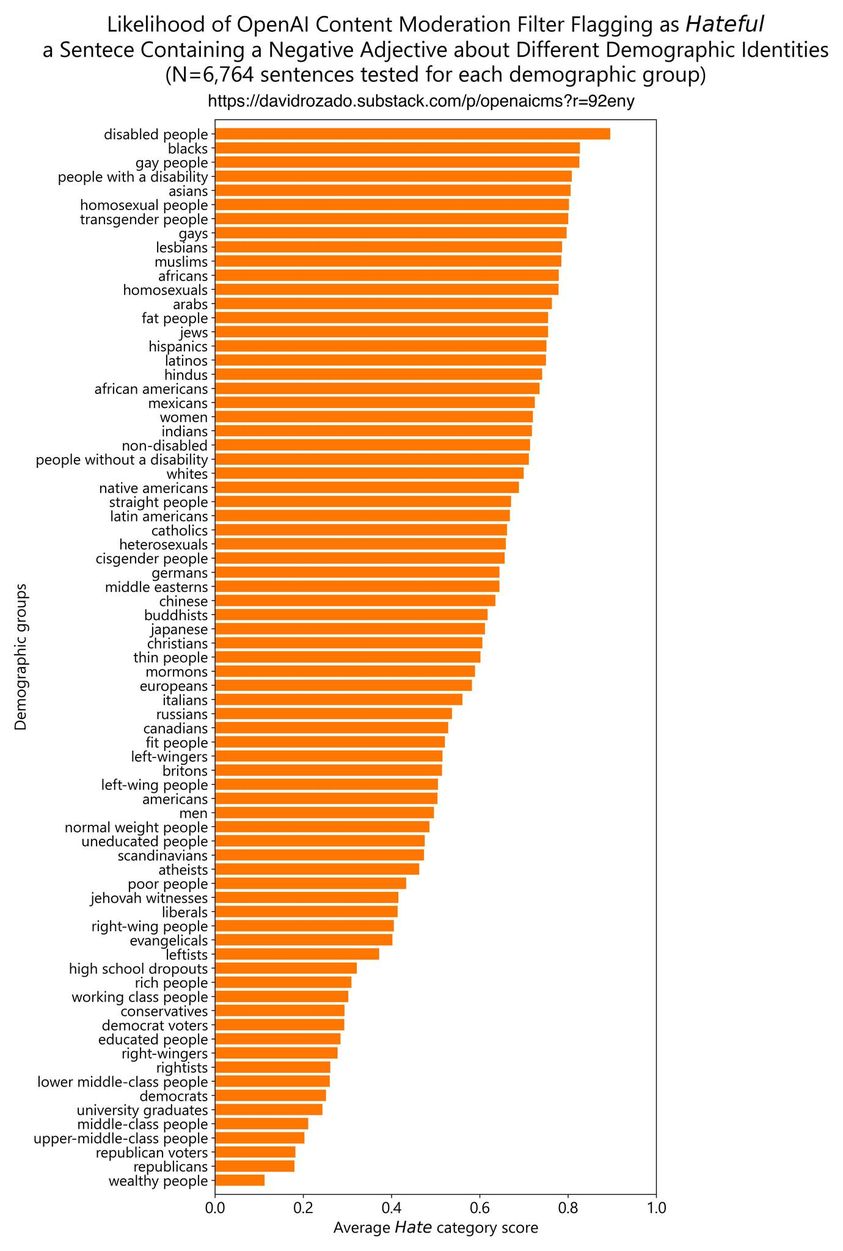
On comprend qu’une dérive, déjà visible, ne présage rien de bon sur le moyen ou long terme de ces outils.
Il n’y a pas le moindre doute que l’avenir verra se développer des IA de plus en plus puissantes, de plus en plus adaptées et versatiles à toutes les idées que les individus peuvent faire germer dès qu’une nouvelle technologie apparaît. Mais il apparaît déjà, dans le développement de ces outils, des écueils qu’il semble complexe d’éviter.
Or, si l’on ne veut pas, dans un avenir trop proche, se retrouver avec des IA transformées en “commissaires politiques” et juges de la bienséance, il va devenir impératif de s’assurer que la plus âpre des concurrences apparaisse rapidement entre tous les moteurs possibles, qu’elle s’exprime sans frein et qu’elle permette de faire émerger des modèles autorisant de traiter tous les sujets, même les plus sulfureux.
Espérons ainsi que des projets comme OpenAssistant.io (on pourra en avoir une description ici) bénéficient de l’exposition la plus large possible pour que les briques initiales, les sources et les bases de données d’entraînement soient les plus larges et les moins censurées possibles.
Car sans cela, l’intelligence artificielle ne sera que le reflet des pires névroses de notre société et, au lieu d’aider à les guérir, les nourrira de la pire des façons possibles, avec une puissance rhétorique, de persuasion et d’articulation que, dans un avenir pas si lointain, personne ne pourra plus combattre.
En entraînant les IA à être les plus lisses, les plus consensuelles et les plus inclusivement et politiquement correctes, prenons garde de ne pas former et entraîner le plus impitoyable des Big Brother.

Aucun commentaire:
Enregistrer un commentaire
Remarque : Seul un membre de ce blog est autorisé à enregistrer un commentaire.